En quoi consistent les modèles de langage ?
Les applications d’IA générative utilisent la technologie des grands modèles de langage (LLM), qui sont un type spécialisé de modèle Machine Learning, que vous pouvez utiliser pour effectuer des tâches de traitement en langage naturel, notamment :
- Déterminer un sentiment ou classifier autrement du texte en langage naturel.
- Résumer un texte.
- Comparer plusieurs sources de texte pour y rechercher une similarité sémantique.
- Générer du langage naturel nouveau.
Bien que les principes mathématiques qui sous-tendent ces grands modèles de langage puissent être complexes, une compréhension de base de l’architecture utilisée pour les implémenter peut vous aider à acquérir une compréhension des concepts de leur fonctionnement.
Modèles de transformateur
Les modèles de machine learning pour le traitement du langage naturel ont évolué au fil des ans. Les grands modèles de langage avancés d’aujourd’hui sont basés sur l’architecture de transformateur, qui s’appuie sur et étend certaines techniques qui ont fait leurs preuves dans la modélisation de vocabulaires pour prendre en charge des tâches de traitement du langage naturel, et en particulier dans la génération de langage. Les modèles de transformateur sont entraînés avec de grands volumes de texte, ce qui leur permet de représenter les relations sémantiques entre les mots et d’utiliser ces relations pour déterminer les séquences probables de texte qui ont un sens. Les modèles de transformateur avec un vocabulaire suffisamment étendu sont capables de générer des réponses en langage qui sont difficiles à distinguer des réponses humaines.
L’architecture du modèle de transformateur est constitué de deux composants ou blocs :
- Un bloc encodeur, qui crée les représentations sémantiques du vocabulaire d’entraînement.
- Un bloc décodeur, qui génère de nouvelles séquences de langage.

- L’apprentissage du modèle est effectué avec un grand volume de textes en langage naturel, provenant souvent d’Internet ou d’autres sources de textes publiques.
- Les séquences de texte sont décomposées en jetons (par exemple des mots individuels) et le bloc encodeur traite ces séquences de jetons en utilisant une technique appelée « attention » pour déterminer les relations entre les jetons (par exemple, quels jetons influencent la présence d’autres jetons dans une séquence, les différents jetons qui sont couramment utilisés dans le même contexte, etc.)
- La sortie de l’encodeur est une collection de vecteurs (des tableaux numériques à valeurs multiples) dans lesquels chaque élément du vecteur représente un attribut sémantique des jetons. Ces vecteurs sont appelés incorporations.
- Le bloc décodeur fonctionne sur une nouvelle séquence de jetons de texte et utilise les incorporations générées par l’encodeur pour générer une sortie en langage naturel approprié.
- Par exemple, étant donné une séquence d’entrée comme « Quand mon chien était », le modèle peut utiliser la technologie de l’attention pour analyser les jetons d’entrée et les attributs sémantiques encodés dans les incorporations pour prédire une complétion appropriée de la phrase, comme « un chiot ».
Dans la pratique, les implémentations spécifiques de l’architecture varient : par exemple, le modèle BERT (Bidirectional Encoder Representations from Transformers) développé par Google pour venir en soutien de son moteur de recherche utilise seulement le bloc encodeur, tandis que le modèle GPT (Generative Pretrained Transformer) développé par OpenAI utilise seulement le bloc décodeur.
Bien qu’une explication complète de chaque aspect des modèles de transformateur dépasse la portée de ce module, une explication de quelques-uns des éléments essentiels d’un transformateur peut vous aider à comprendre comment ils prennent en charge l’IA générative.
Segmentation du texte en unités lexicales
La première étape de l’apprentissage d’un modèle de transformateur consiste à décomposer le texte d’entraînement en jetons, en d’autres termes à identifier chaque valeur de texte unique. Pour faire simple, vous pouvez considérer chaque mot distinct du texte d’apprentissage comme un jeton (bien qu’en réalité, des jetons puissent être générés pour des mots partiels, ou pour des combinaisons de mots et de ponctuation).
Considérons par exemple la phrase suivante :
I heard a dog bark loudly at a cat
Pour tokeniser ce texte, vous pouvez identifier chaque mot discret et leur affecter des ID de jeton. Par exemple :
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
La phrase peut maintenant être représentée avec les jetons : {1 2 3 4 5 6 7 3 8}. De même, la phrase « J’ai entendu un chat » pourrait être représentée comme {1 2 3 8}.
Alors que vous continuez à entraîner le modèle, chaque nouveau jeton du texte d’entraînement est ajouté au vocabulaire avec les ID de jeton appropriés :
- meow (9)
- skateboard (10)
- etc.
Avec un ensemble suffisamment grand de textes d’entraînement, un vocabulaire de plusieurs milliers de jetons peut être compilé.
Incorporations
Bien qu’il puisse être pratique de représenter les jetons comme de simples ID, principalement en créant un index pour tous les mots du vocabulaire, ils ne nous disent rien sur la signification des mots ou sur les relations entre eux. Pour créer un vocabulaire qui encapsule les relations sémantiques entre les jetons, nous définissons pour eux des vecteurs contextuels, qui sont appelés incorporations. Les vecteurs sont des représentations numériques d’informations à valeurs multiples, par exemple [10, 3, 1], dans lesquelles chaque élément numérique représente un attribut particulier des informations. Dans le cas des jetons de langage, chaque élément du vecteur d’un jeton représente un attribut sémantique de celui-ci. Les catégories spécifiques pour les éléments des vecteurs dans un modèle de langage sont déterminées pendant l’entraînement, en fonction de la fréquence d’utilisation des mots ensemble ou dans des contextes similaires.
Les vecteurs représentent des lignes dans un espace multidimensionnel, décrivant la direction et la distance le long de plusieurs axes (vous pouvez impressionner vos amis mathématiciens en les appelant amplitude et magnitude). On peut considérer les éléments d’un vecteur d’incorporation pour un jeton comme des étapes le long d’un chemin dans un espace multidimensionnel. Par exemple, un vecteur à trois éléments représente une trajectoire dans un espace tridimensionnel dans lequel les valeurs des éléments indiquent les unités parcourues avant/arrière, gauche/droite et haut/bas. Globalement, le vecteur décrit la direction et la distance du chemin de l’origine à la fin.
Les éléments des jetons dans l’espace des incorporations représentent chacun un attribut sémantique du jeton, de sorte que les jetons sémantiquement similaires doivent aboutir à des vecteurs qui ont une orientation similaire – en d’autres termes, ils pointent dans la même direction. Une technique appelée similarité cosinus est utilisée pour déterminer si deux vecteurs ont des directions similaires (indépendamment de la distance) et représentent donc des mots liés sémantiquement. Pour prendre un exemple simple, supposons que les incorporations pour nos jetons se composent de vecteurs avec trois éléments, par exemple :
- 4 ("dog"): [10,3,2]
- 8 ("cat"): [10,3,1]
- 9 ("puppy") : [5,2,1]
- 10 ("skateboard") : [-3,3,2]
Nous pouvons représenter ces vecteurs dans un espace tridimensionnel, comme ceci :
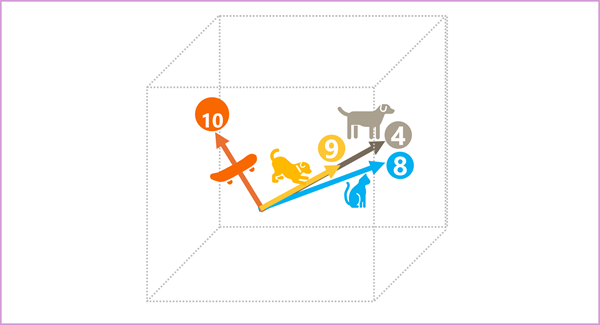
Les vecteurs d’incorporation pour « dog » et « puppy » décrivent un chemin le long d’une direction presque identique, qui est également assez similaire à la direction pour « cat ». En revanche, le vecteur d’intégration de « skateboard » décrit une trajectoire dans une direction très différente.
Remarque
L’exemple précédent montre un exemple de modèle simple dans lequel chaque incorporation a seulement trois dimensions. Les modèles de langage réels ont beaucoup plus de dimensions.
Il existe plusieurs façons de calculer les incorporations appropriées pour un ensemble donné de jetons, notamment des algorithmes de modélisation du langage comme Word2Vec ou le bloc encodeur dans un modèle de transformateur.
Attention
Les blocs encodeur et décodeur d’un modèle de transformateur incluent plusieurs couches qui forment le réseau neuronal du modèle. Nous n’avons pas besoin d’entrer dans les détails de toutes ces couches, mais il est utile de considérer l’une des sortes de couches utilisées dans les deux blocs : les couches d’attention. L’attention est une technique utilisée pour examiner une séquence de jetons de texte et pour essayer de quantifier la force des relations existant entre eux. En particulier, l’auto-attention implique de réfléchir à la façon dont d’autres jetons autour d’un jeton particulier influencent la signification de ce jeton.
Dans un bloc d’encodeur, chaque jeton est soigneusement examiné dans son contexte et un encodage approprié est déterminé pour son incorporation vectorielle. Les valeurs du vecteur sont basées sur la relation entre le jeton et d’autres jetons avec lesquels il apparaît fréquemment. Cette approche contextualisée signifie que le même mot peut avoir plusieurs incorporations selon le contexte dans lequel il est utilisé. Par exemple, « the bark of a tree » a une signification différente de « I heard a dog bark ».
Dans un bloc décodeur, les couches d’attention sont utilisées pour prédire le jeton suivant dans une séquence. Pour chaque jeton généré, le modèle a une couche d’attention qui prend en compte la séquence de jetons jusqu’à ce point. Le modèle prend en compte les jetons qui ont le plus d’influence quand il s’agit de déterminer ce que doit être le jeton suivant. Par exemple, dans la séquence « I heard a dog », la couche d’attention peut attribuer une pondération plus grande aux jetons « heard » et « dog » lors de l’examen du mot suivant dans la séquence :
I heard a dog [bark]
Rappelez-vous que la couche d’attention fonctionne avec des représentations vectorielles numériques des jetons, et non pas avec le texte réel. Dans un décodeur, le processus commence par une séquence d’incorporations de jetons représentant le texte à compléter. La première chose qui se produit est qu’une autre couche d’encodage positionnel ajoute une valeur à chaque incorporation pour indiquer sa position dans la séquence :
- [1,5,6,2] (I)
- [2,9,3,1] (heard)
- [3,1,1,2] (a)
- [4,10,3,2] (dog)
Pendant l’entraînement, l’objectif est de prédire le vecteur pour le jeton final dans la séquence en fonction des jetons précédents. La couche d’attention affecte une pondération numérique à chaque jeton de la séquence jusqu’à présent. Elle utilise cette valeur pour effectuer un calcul sur les vecteurs pondérés, qui produit un score d’attention qui peut être utilisé pour calculer un vecteur possible pour le jeton suivant. Dans la pratique, une technique appelée attention multitête utilise différents éléments des incorporations pour calculer plusieurs scores d’attention. Un réseau neuronal est ensuite utilisé pour évaluer tous les jetons possibles afin de déterminer le jeton le plus probable avec lequel poursuivre la séquence. Le processus se poursuit de façon itérative pour chaque jeton de la séquence, la séquence résultante étant utilisée jusqu’à présent de façon régressive comme entrée pour l’itération suivante, en créant en fait le résultat un jeton à la fois.
L’animation suivante montre une représentation très simplifiée de la façon dont cela fonctionne. En réalité, les calculs effectués par la couche d’attention sont plus complexes, mais les principes peuvent être simplifiés comme suit :

- Une séquence d’incorporations de jetons est introduite dans la couche d’attention. Chaque jeton est représenté sous la forme d’un vecteur de valeurs numériques.
- L’objectif d’un décodeur est de prédire le jeton suivant dans la séquence, qui sera aussi un vecteur qui s’aligne sur une incorporation dans le vocabulaire du modèle.
- La couche d’attention évalue la séquence jusqu’à présent et affecte des pondérations à chaque jeton pour représenter leur influence relative sur le jeton suivant.
- Les pondérations peuvent être utilisées pour calculer un nouveau vecteur pour le jeton suivant avec un score d’attention. L’attention multitête utilise différents éléments dans les incorporations pour calculer plusieurs jetons alternatifs.
- Un réseau neuronal entièrement connecté utilise les scores dans les vecteurs calculés pour prédire le jeton le plus probable à partir de l’ensemble du vocabulaire.
- Le résultat prédit est ajouté à la séquence jusqu’à présent, qui est utilisée comme entrée pour l’itération suivante.
Pendant l’entraînement, la séquence réelle de jetons est connue : nous masquons seulement ceux qui arrivent dans la séquence plus tard que la position du jeton actuellement considérée. Comme dans tout réseau neuronal, la valeur prédite pour le vecteur de jetons est comparée à la valeur réelle du vecteur suivant dans la séquence, et la perte est alors calculée. Les pondérations sont ensuite ajustées de façon incrémentielle pour réduire la perte et améliorer le modèle. Quand elle est utilisée pour une inférence (la prédiction d’une nouvelle séquence de jetons), la couche d’attention entraînée applique des pondérations qui prédisent le jeton le plus probable dans le vocabulaire du modèle qui est sémantiquement aligné sur la séquence jusqu’à présent.
Tout cela signifie qu’un modèle de transformateur comme GPT-4 (le modèle derrière ChatGPT et Bing) est conçu pour prendre une entrée texte (appelée une invite) et générer une sortie syntaxiquement correcte (appelée une complétion). En effet, la « magie » du modèle est qu’il a la capacité de formuler une phrase cohérente. Notez que cela n’implique aucune « connaissance » ou « intelligence » de la part du modèle, mais seulement un vocabulaire étendu et la capacité à générer des séquences de mots significatives. Cependant, ce qui rend un grand modèle de langage comme GPT-4 si puissant, c’est le volume de données avec lequel il a été entraîné (des données publiques et sous licence d’Internet) et la complexité du réseau. Ceci permet au modèle de générer des complétions basées sur les relations entre des mots du vocabulaire sur lequel le modèle a été entraîné; générant souvent un résultat qui ne peut pas être distingué d’une réponse humaine à la même invite.